Ever wondered why stores like Easyday,Big Bazar place confectioneries near the checkout counter ? Or why the dairy products section is always near one corner of the store ? While some answers may seem highly intuitive, the fact of the matter is most are not !
These stores make use of analytics by analyzing your transactions , in order to guess which items go together in the shopping basket.Retailers can use this data in countless ways to increase their revenue.
For example -
1. Store Layout planning (Placing products that go together close by to increase spend per shopping basket and to increase customer shopping experience)
2. Targeted Marketing (Using the data about customers collected to inform them of latest offering which might be of their interest)
This post will try to explain the basic concept behind this form of retail analytics. I have performed the market basket analysis using the apriori algorithm in R.
The dataset for this can be downloaded from here: https://www.dropbox.com/s/n09hu3mr63pq4bw/skusold.csv
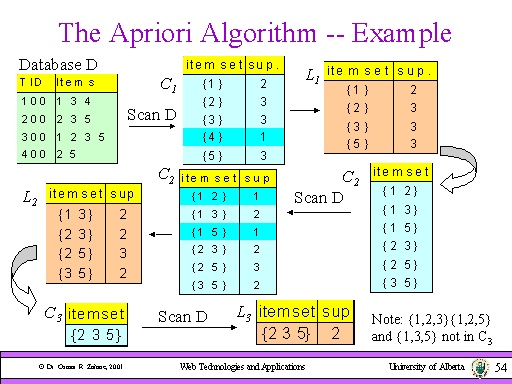
An intro into Apriori Algorithm:
 Courtesy: http://webdocs.cs.ualberta.ca/~zaiane/courses/cmput499/slides/Lect10/img054.jpg
Courtesy: http://webdocs.cs.ualberta.ca/~zaiane/courses/cmput499/slides/Lect10/img054.jpg
Follow the comments alongside the code to understand the flow of logic.
*Text in white is the code.
*Text in blue is the output.
Interpretation of the Rules
lhs rhs support confidence lift
{Eggs} => {Bread} 0.4615 0.857 1 1.393
The support indicates the percentage of occurrence of this transaction in all possible transactions.
The confidence indicates the correctness of prediction and likelihood of purchase.
In this example, if a customer buys eggs then the likelihood that he will buy bread as well is ~ 85%. The support indicates that ~46% of transactions had similar characteristics.
2.Wikipedia - Apriori Algorithm3.Maching learning
These stores make use of analytics by analyzing your transactions , in order to guess which items go together in the shopping basket.Retailers can use this data in countless ways to increase their revenue.
For example -
1. Store Layout planning (Placing products that go together close by to increase spend per shopping basket and to increase customer shopping experience)
2. Targeted Marketing (Using the data about customers collected to inform them of latest offering which might be of their interest)
This post will try to explain the basic concept behind this form of retail analytics. I have performed the market basket analysis using the apriori algorithm in R.
The dataset for this can be downloaded from here: https://www.dropbox.com/s/n09hu3mr63pq4bw/skusold.csv
An intro into Apriori Algorithm:
 Courtesy: http://webdocs.cs.ualberta.ca/~zaiane/courses/cmput499/slides/Lect10/img054.jpg
Courtesy: http://webdocs.cs.ualberta.ca/~zaiane/courses/cmput499/slides/Lect10/img054.jpgFollow the comments alongside the code to understand the flow of logic.
*Text in white is the code.
*Text in blue is the output.
#Market Basket Analysis #Installing package 'arules' for apriori algorithm install.packages("arules")library(arules)install.packages("knitr")library(knitr) #Checking working directory getwd()[1] "C:/Users/Shanky/Documents" #Reading the filett<-read.csv("skusold.csv") head(tt) #It can be seen that there are multiple orders from the same Order ID. Thus, we need to now arrange them in such a manner that all orders pertaining to one transaction are listed together.Order SKU 1 9305 Bread 2 9305 Tropicana 3 9305 Eggs 4 11020 Tropicana 5 11020 Gilette 6 11020 Eggs #Our objective is to group or aggregate the items together based on the Order ID. We can do that as follows:Aggdata<-split(tt$SKU,tt$Order) head(Aggdata) #All items bought from same order ID listed$`9305` [1] Bread Tropicana Eggs Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana $`11013` [1] Bread Tropicana Jam Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana $`11015` [1] Eggs Bread Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana $`11017` [1] Tomatoes AfterShave Tropicana Gilette Eggs Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana $`11018` [1] Jam AfterShave Tropicana Tomatoes Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana $`11019` [1] AfterShave Jam Tomatoes Tropicana Hide Gilette Levels: AfterShave Bread Eggs Gilette Hide Jam Tomatoes Tropicana#For using the Apriori algorithm, we need to coerce the transaction abc = as(Aggdata,"transactions") #Checking the summary statistics of the data summary(abc)transactions as itemMatrix in sparse format with 13 rows (elements/itemsets/transactions) and 8 columns (items) and a density of 0.4712 most frequent items: Bread Tropicana AfterShave Eggs Gilette (Other) 8 8 7 7 7 12 element (itemset/transaction) length distribution: sizes 2 3 4 5 6 2 4 3 3 1 Min. 1st Qu. Median Mean 3rd Qu. Max. 2.00 3.00 4.00 3.77 5.00 6.00 includes extended item information - examples: labels 1 AfterShave 2 Bread 3 Eggs includes extended transaction information - examples: transactionID 1 9305 2 11013 3 11015 #The transaction an itemMatrix forms the input for the Apriori AlgorithmRules<-apriori(abc,parameter=list(supp=0.3,conf=0.8,target="rules",minlen=2))parameter specification: confidence minval smax arem aval originalSupport support minlen maxlen 0.8 0.1 1 none FALSE TRUE 0.3 2 10 target ext rules FALSE algorithmic control: filter tree heap memopt load sort verbose 0.1 TRUE TRUE FALSE TRUE 2 TRUE apriori - find association rules with the apriori algorithm #To view the Rules generatedinspect(Rules)lhs rhs support confidence lift 1 {Tomatoes} => {AfterShave} 0.3077 1.0000 1.857 2 {Jam} => {Tropicana} 0.3846 0.8333 1.354 3 {Eggs} => {Bread} 0.4615 0.8571 1.393 4 {Eggs, Tropicana} => {Bread} 0.3077 0.8000 1.300 5 {Bread, Tropicana} => {Eggs} 0.3077 0.8000 1.486#To inspect items by frequencyitemFrequencyPlot(abc,topN=5,col="red")

{kind=link}
Interpretation of the Rules
lhs rhs support confidence lift
{Eggs} => {Bread} 0.4615 0.857 1 1.393
The support indicates the percentage of occurrence of this transaction in all possible transactions.
The confidence indicates the correctness of prediction and likelihood of purchase.
In this example, if a customer buys eggs then the likelihood that he will buy bread as well is ~ 85%. The support indicates that ~46% of transactions had similar characteristics.
References
1.2.Wikipedia - Apriori Algorithm3.Maching learning
No comments:
Post a Comment