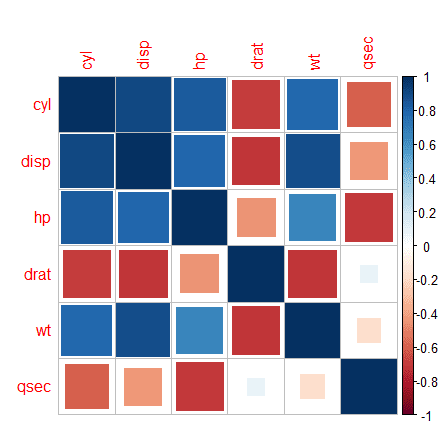
We know that the main verbs for the dplyr package are -
1. select
2. filter
3. arrange
4. summarise
5. group_by
6. mutate
Let us take a simple question and try to find it's solution. While writing the code for this solution, I will demonstrate how R transforms our data. This step by step procedure will make it crystal clear on how to use these different functions together for powerful analyis.
Taking the in-built 'hflights' package for the data analysis.
Let's say we want to find the favourite or most frequented destination for each Carrier.
Code:
Let's split the code at each instance and see the kind of tables that R creates.
Code 1.1

Code 1.2

Code 1.3: Final Result
1. select
2. filter
3. arrange
4. summarise
5. group_by
6. mutate
Let us take a simple question and try to find it's solution. While writing the code for this solution, I will demonstrate how R transforms our data. This step by step procedure will make it crystal clear on how to use these different functions together for powerful analyis.
Taking the in-built 'hflights' package for the data analysis.
Let's say we want to find the favourite or most frequented destination for each Carrier.
Code:
> b <- hflights %>% group_by(UniqueCarrier, Dest) %>% summarise(n = n()) %>% mutate(rank = rank(desc(n))) %>% filter(rank == 1) > b Source: local data frame [15 x 4] Groups: UniqueCarrier UniqueCarrier Dest n rank 1 AirTran ATL 2029 1 2 Alaska SEA 365 1 3 American DFW 2105 1 4 American_Eagle DFW 2424 1 5 Atlantic_Southeast DTW 851 1 6 Continental EWR 3924 1 7 Delta ATL 2396 1 8 ExpressJet CRP 3175 1 9 Frontier DEN 837 1 10 JetBlue JFK 695 1 11 Mesa CLT 71 1 12 SkyWest COS 1335 1 13 Southwest DAL 8243 1 14 US_Airways CLT 2212 1 15 United SFO 643 1Voila ! We have the list of Air Carriers and the most frequented destination by them. But, for a more intuitive understanding -
Let's split the code at each instance and see the kind of tables that R creates.
Code 1.1
b <- hflights %>%
group_by(UniqueCarrier, Dest) %>%
select(UniqueCarrier,Dest)
View(b)
Code 1.2
Code 1.3: Final Result
b <- hflights %>% + group_by(UniqueCarrier, Dest) %>% + summarise(n = n()) %>% + mutate(rank = rank(desc(n))) %>% + filter(rank == 1) > b Source: local data frame [15 x 4] Groups: UniqueCarrier UniqueCarrier Dest n rank 1 AirTran ATL 2029 1 2 Alaska SEA 365 1 3 American DFW 2105 1 4 American_Eagle DFW 2424 1 5 Atlantic_Southeast DTW 851 1 6 Continental EWR 3924 1 7 Delta ATL 2396 1 8 ExpressJet CRP 3175 1 9 Frontier DEN 837 1 10 JetBlue JFK 695 1 11 Mesa CLT 71 1 12 SkyWest COS 1335 1 13 Southwest DAL 8243 1 14 US_Airways CLT 2212 1 15 United SFO 643 1